
背景
线上系统的日志能够记录线上服务的详细信息包括请求参数,返回的结果,处理过程中出现的错误信息等等。这些信息能够帮助我们debug线上问题,根据错误日志发出报警,将线上日志回放到测试环境也能为测试提供数据源。同时,日志记录的用户行为,也能够帮助我们分析用户,产出报表,通过数据挖掘来进一步优化系统。为此,我们需要能够对日志进行高效的利用。
日志的高效利用往往包括以下几个方面:
? 日志打印:线上服务模块按照日志规范将日志打印到本地磁盘
? 日志采集:将各个服务打印的日志统一收集起来
? 日志聚合:把业务上相关联的日志聚合到一起
? 日志分析:对日志进行分析,定位线上问题,发出报警,挖掘用户行为,回放日志到测试环境等
阅文集团搜索团队在以上几个方面都做了一些工作,整体的日志架构如下图所示:
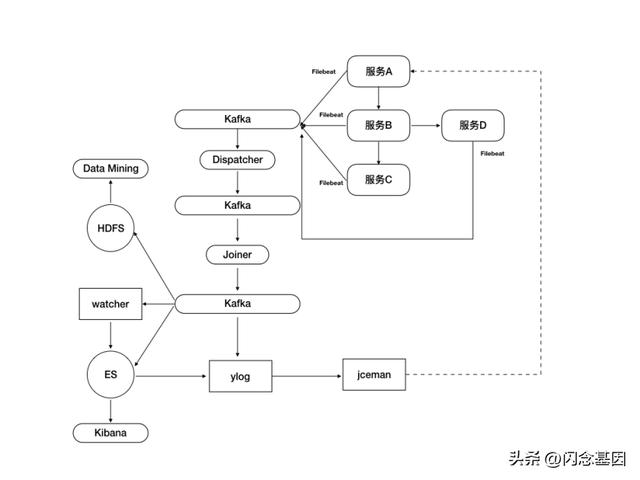

我们利用filebeat从各个服务实时采集日志,传输到Kafka中,并通过流式计算对日志进行聚合。聚合好的日志一方面写入到HDFS上作为离线日志供后续数据挖掘用,另一方面写入到ElasticSearch中进行实时查询。在此基础上,我们开发了ylog,jceman和watcher来对日志进行分析,回放和监控。
我们将分上下两篇文章对以上几个方面进行展开,上篇将主要介绍日志打印规范和日志采集的相关工作,下篇将介绍日志聚合,以及我们为提高日志使用效率而开发的几个工具。
日志打印
解析日志一直以来都是一个头疼的问题,其本质原因在于日志打印得不规范,太过于随意。这就使得日志解析的代码需要考虑各种情况,代码也难以维护。另一方面,日志格式发生变化时,往往需要修改相应的解析代码,而日志的变动通常又很难及时通知到下游需要解析日志的各方,往往只有当下游日志解析出现问题时才会发现日志格式已经变更。为此,我们为日志打印制定了一套规范。
日志规范
日志规范主要包括几个方面:日志分等级,记录关键信息,日志格式需要易于解析,日志按时间/大小滚动。
日志等级
结合业界经验和我们自身的情况,我们将日志分为以下4个级别(日志级别从低到高):
? DEBUG日志:记录程序运行的关键过程,用于对线上问题进行debug
? INFO日志:记录接收到的请求上下文,服务返回的响应等关键信息
? W***RN日志:请求处理过程中发生了错误,但这些错误不会影响后续请求的处理,记录相应的错误信息
? ERROR日志:请求处理过程中发生了致命错误,导致进程需要退出,记录相应的错误信息
业界除了以上分类外,其它常见的分类还包括TR***CE,NOTICE和F***T***L,可以参见这个链接(https://stackoverflow.com/questions/2031163/when-to-use-the-different-log-levels)了解更多日志等级的区别。
我们可以通过配置文件来控制日志打印的最低级别,系统会打印所有大于等于该配置级别的日志,小于该等级的其它类型日志则不会打印。例如,配置为INFO级别时,系统会打印ERROR,W***RN和INFO日志,但不会打印DEBUG日志。通常我们线上会配置日志打印级别为INFO。
关键信息
日志应该只记录关键信息,日志分等级后,不同等级的日志也只应该记录该等级相关的关键信息。如果一股脑儿把各种信息都写入到日志里,会增加磁盘写入的量(尽管现在磁盘大小往往不是问题,但如果服务有其他需要读写磁盘的工作,那么仍然会带来磁盘资源的竞争),也会增加后续传输日志,解析日志的量。另一方面,无关的日志太多,也会往往会对关键信息造成干扰,影响我们对日志的分析。
结合我们的经验,通常我们会在日志中记录以下信息:
? 服务名字:在关联多个日志源时,区分不同的日志
? 接收到请求的时间:用于分析请求的时间分布,从时间维度上对日志进行筛选和统计,例如:系统承接的QPS,PV等
? 日志级别:INFO, W***RN, ERROR, DEBUG
? 线程ID:用于线上问题调试
? 打印日志的文件名,函数名,行号:用于线上问题的调试
? 请求来源的IP和端口:用于追踪线上请求
? 处理请求花费的时间: 用于统计请求处理的时间,发现系统的处理瓶颈,分析系统的响应时间分布等
? 请求的logid:用于关联不同模块的日志
? 请求的request和response:记录服务接收到的请求和返回的响应
? 错误信息:对于W***RN和ERROR日志,尽可能详细的记录错误信息,便于后续定位问题。
请求的request数据应该尽可能全的记录下来,一方面有助于后续的日志分析,也利于复现线上问题,生成回归测试用例。response如果太大,则只需要记录主要信息,忽略次要信息,例如,可以把返回数据的id记录下来,数据的详情则可以忽略。logid用于关联不同模块的日志,下文将详细介绍logid,同时W***RN和ERROR日志也应该带上logid,以便将错误信息和对应的请求关联起来。
日志频次
为了便于日志的统计,减少日志量,我们规定:
? INFO日志:处理一条请求,打印一条INFO日志,记录该请求的信息和返回的响应
? W***RN和ERROR日志:根据业务处理逻辑发生的错误,打印相应的日志,不做强制要求
? DEBUG日志:平时关闭DEBUG日志,当需要对线上问题进行定位时,才动态开启DEBUG日志,问题解决后,动态关闭DEBUG日志
每个请求只打印一条INFO日志,便于后续的日志统计和分析:简单通过统计INFO日志的条数就可以统计出服务的QPS,只需要分析一条日志就可以获取该请求的所有信息。DEBUG日志往往会打印很多信息,但在后续的日志分析中却不会用到,因此正常运行程序时不需要打印。
易解析
前文我们提到,打印的日志需要易于解析,否则后续维护成本会很高。这里的“易解析”,除了易于代码解析外,还应该易于“人眼解析”。毕竟日志很大的一个用处是debug线上问题,而进行debug工作的终究还是人,因此我们需要以人为本,让人眼能够快速解析出日志,定位问题。当然,易于代码解析和易于人眼解析这两个要求往往会有所冲突,我们需要在两者间进行权衡。
无论是易于代码解析还是易于人眼解析,都需要日志是格式化好的。为了易于人眼解析,我们往往还要求是按照pretty模式格式化好的日志。这里我们选择采用JSON来格式化日志,该格式既便于代码解析,也便于人眼解析。但因为多条日志打印在一个文件里,pretty模式的JSON日志(一条记录多行)不利于代码解析。为此,我们要求每条日志(JSON)只打印一行。这也是易于代码解析和易于人眼解析之间的一个trade-off。
如前所述,日志格式变更,可能会导致下游的解析工作失败。而我们采用JSON格式打印日志后,下游的解析工作可以很容易的进行容错和兼容。如果需要使用日志的某个字段,那么我们只要判断该字段是否存在,字段类型是否匹配,就可以判断出日志格式是否发生变化。同样,日志新增字段也不会给解析工作带来影响,我们只需要忽略不认识的字段即可。
日志滚动
如果所有日志都打印到一个文件中,会导致日志文件过大,不利于后续的日志采集和删除。为此,我们需要对日志进行切分。通常有两种切分方式,一种是按照日志文件大小切分,当日志大小达到一定阈值时,就打开一个新的文件来记录日志。另一种是按照时间来切分,每隔指定的时间(每天/每小时),打开一个新的文件来记录日志。当然,如果日志量非常大,也可以利用这两种结合的方式来切分,即:先按照时间切分,在一个时间段内,如果日志量超过给定的阈值,那么进一步按照大小切分。
我们线上日志采用了小时级别切分,保留最近2天的日志,过期的日志,会通过定时脚本删除。
本地日志 vs 远程日志
以上我们讨论的都是将日志打印在本地,还有一种方式是(通过网络传输)直接将日志打印到远程服务器上。后者需要服务进程启动时创建到远程日志服务的链接,当有日志需要打印时,将日志发送到远程服务器(为了不影响线上请求的处理,往往通过异步方式发送日志)。这个过程通常由底层的日志库来封装,对上层业务透明。打印远程日志的方式存在一些问题。首先,它使得线上服务和远程日志服务耦合,如果访问远程服务出现问题可能会影响线上服务的正常运行。其次,如果和远程服务之间的通信出现问题,那么日志库还需要缓存未能成功发送的日志,为了减轻缓存日志对内存带来的影响,我们往往需要将日志缓存在磁盘上,甚至在打印日志时同时打印到本地和远程,这都加大了日志库的设计复杂度(可以参见下文中,实现日志采集需要面对的问题)。
为此,我们选择直接在打印日志到本地,将日志打印和日志采集解耦,使用专门的工具来采集日志。
日志采集
日志打印到磁盘后,我们不能直接在线上服务所在的节点上去直接操作日志。这主要有几个方面考虑,首先,直接在操作线上节点很危险,如果我们在处理日志的时候对线上文件进行了误修改,或者误删除,那么会给线上服务带来灾难性的问题;其次,在线上对日志进行分析时,往往会占用机器的CPU,内存,磁盘等资源,这会挤压线上服务的资源,带来不确定性;最后,现在很多业务都微服务化了,一次请求往往会由多个微服务处理,每个微服务为了冗灾往往又存在多个实例。因此当系统出现问题时,我们很难快速定位到出现问题的服务所在的实例,这就导致我们需要登陆很多节点去查看日志,这往往是一个非常头疼的事情。为此,我们需要将日志从线上服务节点采集起来。
如何优雅的采集日志
很多场景需要对日志进行实时分析,因此日志的采集也需要做到实时。日志的实时采集看上去很简单,只要我们不断去检查日志是否更新(类似于Unix的tail命令),然后把更新的数据通过网络发送出去就可以了。但实际上这里面有很多工程细节需要考虑。
? 因为是对线上节点日志的采集,因此最重要的一点是,日志采集不应该影响线上服务,只能使用较少的资源来采集日志
? 日志采集需要有很高的性能,能够尽快将日志传输出去,保证日志的实效性
? 当采集服务发生错误意外退出后,如何容错,如何恢复日志传输?
? 如何保证消息传输的正确性:是否保证日志的顺序?日志是否丢失或重复(***t-Least-Once, ***t-Most-Once, Exactly-Once)?
? 日志滚动有多种实现方案,需要优雅地处理各种方案
? 如果下游出现问题(来不及处理,甚至直接宕机),无法接收请求,如何处理?
日志采集应该使用尽量少的资源,尽量高效的传输日志,这两个目标存在一些冲突,需要在技术选择上进行权衡。为此,很多开源方案都开始转向使用一些高性能的编程语言来实现日志采集。例如采用Go语言编写的Filebeat来取代java编写的Logstash,采用C语言编写的Fluent Bit取代Ruby编写的Fluentd。我们可以通过多线程(进程)来传输日志,但这可能会增加CPU的压力。为了减少CPU的占用,我们在检测日志文件是否有更新时,也不能过于激进,但检测太过保守又可能导致日志传输延迟。为了提升传输效率,减少带宽,我们可以通过把多条日志批量合并,压缩后传输,但批量后可能会影响日志传输的实效性,压缩可能会带来CPU上的消耗。
为了保证错误发生后,恢复日志传输,我们需要建立日志传输进度的check point,并将check point进行持久化,这样才能保证日志不丢失。如果每传输一条日志都更新check point,并刷新到磁盘,会给磁盘带来压力,同时也会影响性能。但如果两次刷新checkout point之间的时间较长,这之间发生错误退出后,恢复日志传输时可能会导致日志重复。为了保证日志的顺序,我们可能还需要对日志进行编号,并考虑多线程/进程传输时如何保证编号的顺序。
除此之外,日志滚动时,有的方案是写一个新的文件,有的方案是继续写原有文件,但定期将原有文件mv成其他名字的文件。当下游太忙,处理不过来时,上游日志采集模块是否能主动发现,还是需要下游模块通知上游,然后降低传输的速率。如果下游宕机,日志采集模块还需要以合适的间隔重试,并报警。
以上这些问题都是日志采集需要考虑的,所以要实现一个看似简单的日志采集,其实会涉及到非常多的工程决策。幸运的是,目前有很多开源的方案可供选择。这其中成熟的开源方案往往会把以上这些问题配置化,让用户根据自身的业务场景,资源情况来优化日志的采集。
选型
我们调研了Logstash,Filebeat,Fluentd,Fluentd Bit,Flume等多个开源的日志采集工具。对于Logstash其性能不是很好,并且很重,为此我们首先将其排除掉。Flume基于java,也比较重,同时其社区活跃度不是很高,因此我们也不做考虑。Fluentd基于Ruby,性能不如Fluent Bit,也不做考虑。Fluent Bit和Filebeat都是比较轻量级的日志采集工具,两者不论是社区活跃度,性能,还是成熟程度都比较好,同时也都支持将日志输入输出到各个中间件/数据库中。
考虑到我们较多的使用到了Elastic Stack的相关组件,包括Elastic Search,Kibana等,而Filebeat也是Elastic Stack的一部分,因此我们最终选择了Filebeat作为日志采集工具。Filebeat也能够实现前文提到的“优雅采集日志”的各个技术点,并将其配置化,因为篇幅限制,这里就不做进一步展开,具体可以参见相关文档(https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-filestream.html)。
日志去哪儿了
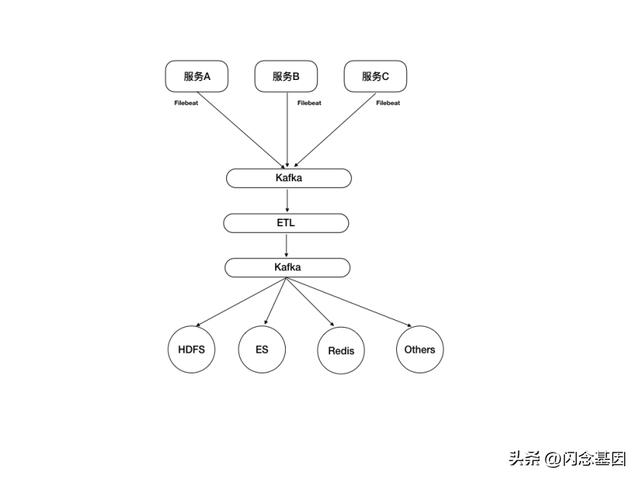
日志从各个服务节点采集后,应该传输到哪里去呢?通常,根据用途不同,我们往往需要将日志传输到不同的下游模块。例如,如果需要对日志进行批量的离线分析,我们可以将其传输到HDFS,如果需要对日志进行检索,我们可以将其传输到Elastic Search,等等。但我们不应该让服务节点直接将日志文件同步给多个下游模块,因为这会带来很多问题。首先,这会抢占线上服务更多的资源(一份日志被多个日志拉取进程读取多次,传输多次)。其次,我们在使用日志之前,通常需要对日志进行ETL操作,如果直接把日志传输给多个下游,而不同的下游模块如果执行了不同的ETL,那么就会导致数据的不一致。最后,多个日志采集进程独立采集,会给日志管理带来混乱。
为此,我们将日志采集后,传输到Kafka中,然后通过流式计算,对日志进行统一的ETL,下游模块从Kafka订阅日志。这样一来确保线上服务节点只传输一份日志,减轻线上服务节点的资源压力,另一方面,日志也能统一维护,使用统一的规则来清洗,确保数据在各个下游模块保持一致。
总结
线上日志是非常重要的资产,有助于我们定位线上问题,监控线上服务,分析用户行为,产出报表,帮助我们优化系统。本文从日志打印和日志采集两个方面介绍了阅文集团搜索团队的一些实践经验,在后续的文章中,我们将从日志聚合和日志分析工具两个方面做进一步的探讨。
作者介绍
刘四维
目前就职于阅文集团智能业务中心,智能业务后端技术负责人
来源:微信公众号:阅文技术
出处:https://mp.weixin.qq.com/s/4kRWCS6-KtiZXyPMbTBTBg

如若转载,请注明出处:https://www.xiegongwen.com/86888.html
相关推荐
-
双十一光棍节图片,双十一光棍节图片朋友圈
我是老师我是医生家属,我愿意把发生在我身边的故事,讲给你听。 商家造节,“双十一”是其中之一吧,你造“购物节”,我蹭热度来个“光棍节”!你光棍我脱单,大路朝天各走一边! 那是个阴惨…
-
党员申请书,党员申请书该怎么写模板
1. 背景介绍作为一名在政府机关工作十年以上的公务员,我深刻体会到党员的重要性和使命。过去的十年中,我积极参与各项工作,并切实感受到党的领导力量。我深知党员身份的荣耀和责任,决定申…
-
田径运动会作文600字优秀作文大全,田径运动会作文600字优秀作文高中
我很小的时候就喜欢跑来跑去。 每天都跑到院子旁边的解放军马厩里,站在马的面前看着它们发呆。我没有看见过它们奔跑,马厩前的空地很小,它们只是溜达,但是我知道它们跑得飞快。 我想骑着它…
-
关于战争的诗歌现代诗,关于战争的诗歌现代诗歌
咏俄乌战争 胡新年 1 男儿有泪不轻弹,只因未到乌克兰。 炮火连天家园毁,城乡处处尸骨寒。 2 作死还数乌克兰,亲美反俄如自残。 强龙岂压地头蛇,大祸临头一瞬间。 3 美帝本质是拱…
-
政治意识不强(政治意识不强的主要表现及整改措施)
政治意识薄弱的影响及加强政治意识的措施 在当今社会,政治意识对每个人来说都是重要而必要的。然而,随着信息的快速传播和个人生活的繁忙,许多人的政治意识却呈现出不强的趋势。本文将探讨政…
-
亲子日记家长篇示范文,亲子日记家长篇
1. 一场难忘的亲子日记活动 今天是亲子日记活动的第一天,我带着我的孩子参加了这个活动。作为一位公务员,我平时工作繁忙,时间都用在了工作上,很少有机会和孩子共度时光。这次亲子日记活…
-
运动会介绍词(社区运动会介绍词)
社区运动会介绍 近年来,随着人们健康意识的增强和生活水平的提高,社区运动会已经成为一个越来越受欢迎的活动。社区运动会旨在通过集体参与体育运动,促进邻里之间的交流和合作,增强社区凝聚…
-
路作文800字,路作文800字叙事
一直跟女儿说无论什么创作,无论是写作、画画或者手工,你就是这个小世界的王,人事物都听你指挥,剧情由你导演,场景由你编排,你要做的就是尽可能让这个小世界,生动有趣稳妥周全且有鲜明的主…
-
树立正确的人生观价值观世界观,树立正确的人生观论文1000字
1. 坎坷的初期作为一位公务员,我曾经历了许多坎坷的初期。刚开始工作时,我对于自己的职责范围和工作内容理解不深,常常迷茫不已。每天繁忙的工作让我感到疲惫不堪,甚至开始怀疑自己是否适…
-
塞鸿秋浔阳即景,塞鸿秋浔阳即景拼音版
唐德宗建中年间,朝中一位大臣刘震的外甥叫王仙客。仙客小时,父亲去世,他便随母亲住在舅舅家。 刘震有个女儿,叫无双,与仙客年纪差不多。两人小时常在一块玩耍,十分亲密。刘震一家待仙客母…